
新型コロナウイルスのゲノム解析について
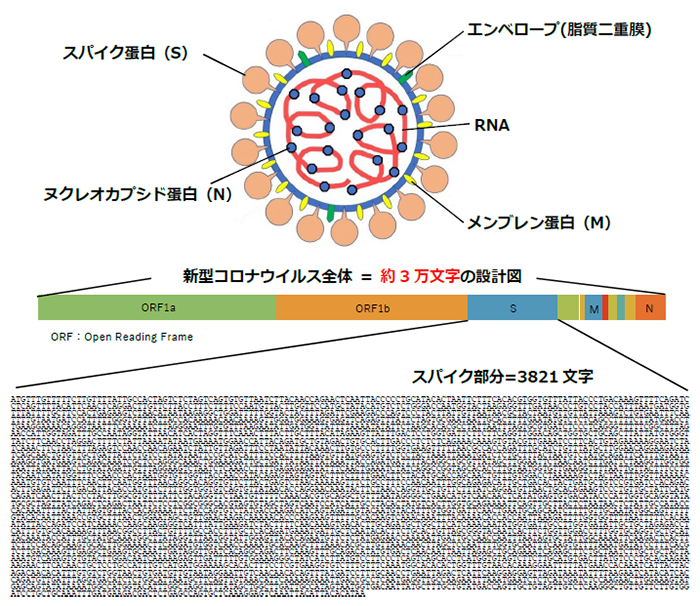
新型コロナウイルスはエンベロープという脂質(油成分)の膜の中に一本鎖のRNA(ウイルスの設計図)が入った構造をしており、ウイルス表面には多くのスパイク蛋白が突き出しています。スパイク蛋白はヒトの細胞表面にある特有の蛋白(レセプター)にくっつくことで細胞内に侵入していきます。また、スパイク蛋白が変化すると細胞へのくっつきやすさも変化します。
新型コロナウイルスはこのように様々な蛋白質から構成されており、その蛋白は約3万文字の塩基(アデニン:A、シトシン:C、グアニン:G、チミン:T)からなる設計図(ゲノム情報)を基に作られます。スパイク蛋白はそのうちの3821文字を基に作られています。
新型コロナウイルスの構造
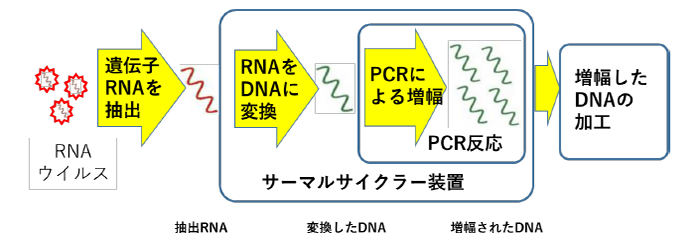
この約3万文字の塩基を決めるのには、次世代シーケンサー(Next Generation Sequencer:NGS)という装置を用います。また、決定された約3万文字の塩基は国立感染症研究所の病原体ゲノム解析研究センターにデータを送り、解析してもらいます。
新型コロナウイルスのゲノム解析の流れ
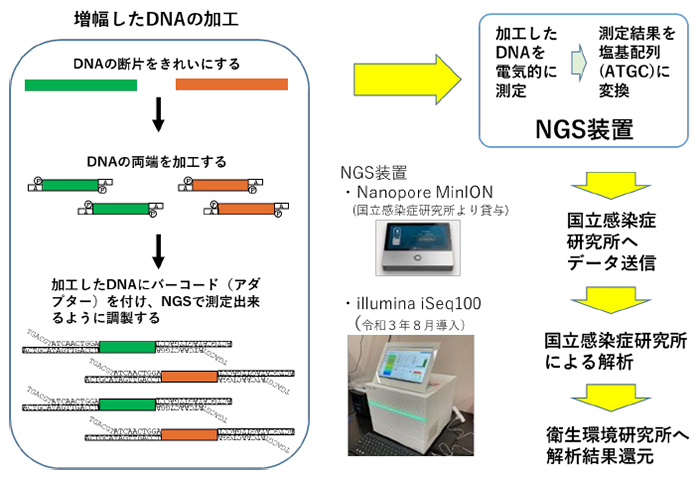
解析は、決定された約3万文字の塩基について、2019年12月30日に中国武漢で検出された新型コロナウイルス(hCoV-19Wuhan/WIV04/2019)の約3万文字と比較し、どこがどういう風に違っているかを調べて変異株(デルタとかオミクロン)を決定します。
同じように、世界で検出されている新型コロナウイルスの約3万文字とも比較して、宮崎県で流行している新型コロナウイルスがどういう系統に属しているか(BA.2系統とかBA.5系統とかXBB系統)を調べ、広く県民へ情報を還元しています。








